
По словам Каспера Линдскоу, главы отдела по работе с искусственным интеллектом JP/Politikens Media Group, проект под названием Platform Intelligence in News (PIN) предназначен для достижения трех стратегических целей:
- повысить редакционную и коммерческую ценность за счет использования ИИ для создания обновленного продукта – ekstrabladet.dk с более широким, глубоким и насыщенным подходом к работе с новостями;
- внедрять ИИ-системы, соответствующие редакционным стандартам, и контролировать использование этих технологий;
- продвигать здравый подход к использованию ИИ в средствах массовой информации, делясь своим опытом и идеями.
«Мы изначально планировали использовать искусственный интеллект и в редакционной работе, и в бизнесе. Наша редакционная миссия расширяется за счет создания более глубокого и насыщенного информационного пространства, где читатели смогут получать актуальный и качественный контент, в полной мере соответствующий нашей редакционной политике. Кроме того, наша бизнес-стратегия строится с учетом увеличения доходов от рекламы и растущей базы подписчиков в результате увеличения трафика и продаж подписок, а также снижения оттока», – поясняет Линдскоу.
В рамках этого проекта команда PIN сосредоточилась на трех типах ИИ, чтобы сформировать новый подход работы с новостным контентом.

Каспер Линдскоу: «Мы охотно делимся полученными знаниями в области искусственного интеллекта. Общая цель издателей – добиться нормализации использования ИИ в медиаиндустрии»
Рекомендательные системы
Ekstra Bladet внедрила системы рекомендаций, управляемые ИИ, чтобы помочь читателям находить актуальные новости в быстро меняющейся цифровой среде. В отличие от развлекательных платформ, где «срок годности» контента гораздо больше, новостные статьи быстро теряют актуальность.
Команда PIN разработала рекомендательные модели, в которых сочетаются востребованность и персонализация, соблюдается целостность информации и исключаются ошибки при фильтрации.
Архитектура рекомендательной системы Ekstra Bladet включает несколько моделей:
- Модели коллаборативной фильтрации предсказывают предпочтения пользователей на основе поведения аудитории в целом. Они эффективны для выявления популярного контента, однако смещают акценты на тренды.
- Модели фильтрации на основе контента анализируют метаданные статей, используя классификацию по темам, распознавание именованных сущностей (NER) и анализ настроений, чтобы рекомендовать статьи на основе индивидуальной истории чтения. Они помогают выявить нишевый контент, но требуют смягчения результатов, поскольку в рекомендациях слишком выделяются те или иные предпочтения.
- Гибридные модели сочетают коллаборативную фильтрацию и фильтрацию на основе контента и нацелены на соблюдение баланса между востребованным контентом и персонализацией.
- Модели сходства, основанные на сравнительном обучении, оценивают сходство статей, используя методы глубокого обучения, и гарантируют, что рекомендации действительно отражают тематическую согласованность, а не основаны на простом сопоставлении ключевых слов.
Главная страница сайта Ekstra Bladet была поделена на несколько частей, каждая из которых стал управляться различными моделями ИИ. Так, верхние блоки, где представлены горячие новости, управляются моделями коллаборативной фильтрации; средние блоки, ведущие на нишевые статьи, – моделями фильтрации на основе контента; основные разделы с важными аналитическими материалами – гибридными моделями.
Внедрение этих систем позволило существенно повысить вовлеченность пользователей:
- на 110% увеличилось количество бесплатных статей;
- на 38% увеличилось число читателей платных статей;
- на 35% увеличилось число конверсий в подписку.
A/B-тестирование позволило получить ключевую информацию о производительности различных моделей. Модели коллаборативной фильтрации обеспечивают высокую вовлеченность, но при этом продвигают уже популярные истории. Модели, основанные на контенте, улучшают поиск нишевого контента, но создают риск возникновения пузыря фильтров. Гибридные модели предлагают наиболее сбалансированный подход, повышая персонализацию.
Обработка естественного языка (NLP)
В Ekstra Bladet используют NLP для улучшения поиска контента, автоматизации тегирования метаданных и улучшения качества рекомендаций к статьям. Основная цель – динамично отображать связанные с новостями сюжеты, позволяя читателям глубже изучать темы, не полагаясь на явные предпочтения пользователей.
Команда PIN внедрила различные модели NLP, каждая из которых была адаптирована для конкретных задач, связанных с новостным контентом:
* Модели классификации тем: нейронные сети сортируют статьи, что позволяет структурированно классифицировать новостные темы.
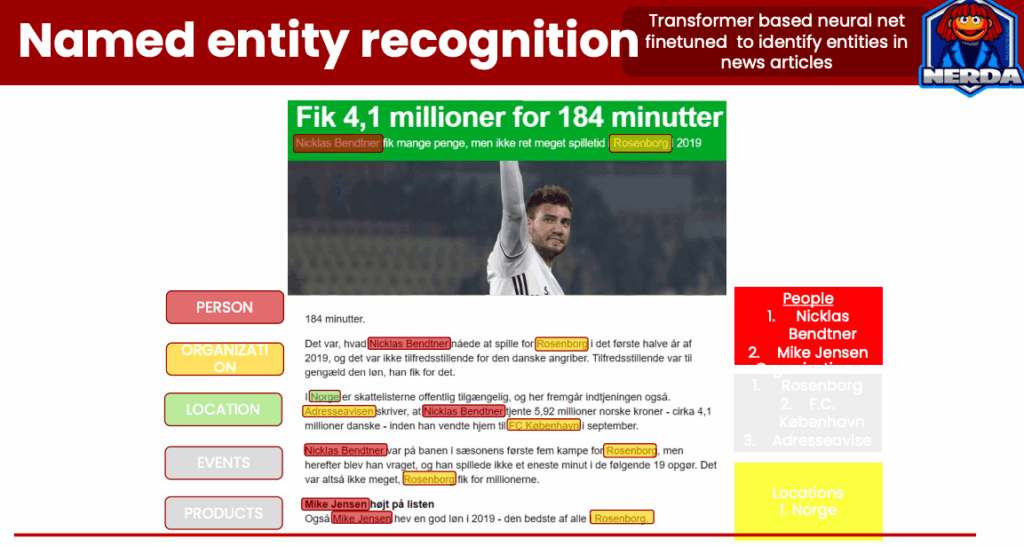
- Распознавание именованных сущностей (NER): система автоматически идентифицирует и помечает объекты (например, людей, организации, местоположения) в статьях, что способствует улучшению индексации и поиску связанного контента.
- Модели анализа настроений: эти модели оценивают эмоциональный тон статей, помогая в подборе контента и таргетинге рекламы.
- Модели сходства, основанные на сравнительном обучении: они значительно улучшают рекомендации по статьям на определенную тему, оценивая контекстуальное сходство, выходящее за рамки простого совпадения ключевых слов.
Их использование привело к 120-процентному увеличению трафика от предлагаемых статей на ту или иную тему. Более точное распознавание объектов повысило качество персонализации и дало возможность читателям быстро отслеживать интересующие их темы. Улучшенный семантический таргетинг рекламы позволил размещать объявления с соблюдением конфиденциальности без отслеживания пользователей. Автоматизация поиска и добавление тегов сделала старые статьи более востребованными.
Генерация естественного языка (NLG)
Чтобы улучшить качество журналистских материалов, при этом сохраняя за ними редакционный контроль, и расширить их охват, в Ekstra Bladet применяют NLG. Команда PIN разработала редакционный набор ИИ-инструментов, названный Monitoring and Assisted Generation of News Artefacts (MAGNA). Эта система развивалась поэтапно:
- Автоматизация на основе правил (GOFAI). Изначально Ekstra Bladet использовала систему AX Semantics, основанную на правилах, для создания кратких новостных заметок на локальную тематику: о задержках в движении поездов, погоде, сделках с недвижимостью и т. д.
- Обобщение с использованием гибридного ИИ. В 2023 году были интегрированы GPT-модели OpenAI. Генерация, дополненная поиском (RAG), дала возможность выпускать контент, созданный с помощью ИИ, который основывался на фактических данных из архивов Ekstra Bladet.
- Оперативное рецензирование. Редакторы просматривали резюме, сгенерированные с помощью ИИ, перед публикацией. Отклоненные резюме учитывались в последующих генерациях, повышая их точность.
Инструмент генерации заголовков и анонсов увеличил вовлеченность аудитории. Оперативная проверка значительно повысила достоверность контента, созданного с помощью ИИ, сократив количество ошибок в четыре раза. Журналисты получили возможность экономить время и сосредоточиться на подготовке больших статей.

Обучение и тестирование
Команда PIN разработала собственную технологию машинного обучения и установила партнерские отношения с университетами, предоставив доступ к данным, необходимым для создания и комплексной оценки ИИ-систем.
При настройке набора рекомендательных систем во время полномасштабного внедрения в 2023 году учитывались результаты более чем 50 A/B-тестов влияния различных систем на поток новостей. «Эти тесты, в числе прочего, показали, что наши модели коллаборативной фильтрации фокусируются в значительной степени на наиболее популярных новостных сюжетах, в то время как модели фильтрации на основе контента выдают рекомендации, не способные сильно удивить читателей чем-то новым», – отмечает Линдскоу.
При обучении и внедрении NLP-моделей они опирались на систему оценок, разработанной командой PIN, которая определяла влияние различных методов обучения на точность, эффективность и полезность моделей. «Это позволило нам внедрить NLP-модели со сбалансированным соотношением точности и эффективности», – говорит Линдскоу.
Наконец, при разработке ИИ-систем, основанных на NLG, они проводили тестирования в ручном и автоматическом режимах, чтобы свести к минимуму фактические ошибки, попадающие в новостной контент. По словам Линдскоу, результаты этих тестов побудили их использовать методику машинного обучения Human-in-the-Loop (HITL) и добиться того, чтобы все инструменты генеративного ИИ, которыми пользуются в редакции, опирались на архив статей Ekstra Bladet, а не полагались на внутренние «знания» GPT-4.
Он добавляет, что в JP/Politikens охотно делятся полученными знаниями в области ИИ: «Общая цель издателей – добиться нормализации использования искусственного интеллекта в медиаиндустрии. Мы опубликовали, в частности, некоторые из наших алгоритмов NLP и базовые алгоритмы рекомендательных систем».
Извлеченные уроки
«Проект PIN – это путешествие по неизведанной территории с большим количеством A/B-тестов. И мы вынесли из него ряд важных уроков.
Во-первых, не все рекомендательные системы, которые эффективно работают в других медиасекторах, подходят для новостных СМИ. Например, коллаборативная фильтрация, которую использует Netflix, в стремительно меняющейся новостной среде часто дает эффект «холодного запуска» (ситуация, когда для корректной работы системы не хватает информации). Здесь лучше всего подойдут рекомендательные системы, основанные на контенте, с использованием NLP.
Во-вторых, нужно учитывать, что рекомендательные системы могут по-разному влиять на читательскую аудиторию. Так что мы используем различные системы, чтобы соответствовать нашим редакционным стандартам и удовлетворять разнообразные потребности читателей», – рассказывает Линдскоу.
Кроме того, в 2023 году они обнаружили, что генеративный ИИ, такой как ChatGPT, выдает гораздо меньше ошибок, когда привязан к базам данным. Поэтому в компании следят за тем, чтобы такие редакционные ИИ-инструменты опирались в первую очередь на их собственные данные.
